
書類をPDFでスキャンすれば「Adobe Acrobat」でテキスト化(OCR)できる
1年以上前の記事です。内容が古い可能性があります。
どういうことかというと、まずは説明したいと思います。
最近のプリンターには複合機と言ってプリンターだけの機能ではなく、スキャナやコピー、中にはファクスにまでなってしまうインクジェットプリンターもあります。
そういったプリンターの中にはスキャンしたデータをPDFもしくはJPEGにしてSDカードに保存してくれるといったものもあります。
わざわざパソコンを繋いだりしなくてもSDカードにスキャンしたデータを保存できるんです。
で、そういったプリンターを使って書類をPDFでスキャンします。
スキャンしたPDFのデータは「Adobe Acrobat」で開くことができます。
で、このAcrobatで画像データの文字をテキストデータに変換することができるというわけ。
そう、つまり、OCRの機能をいつのまにかAcrobatは持っていたんですね。

さっそく使ってみての感想です。
- ファイルでまとめて変換できるのでページで変換するよりもひとまとめにしてしまってから変換した方が楽。
- 数字での誤変換が多かった。特に縦書き内の二桁数字。
- ヌキ文字は検知できない模様。

青字に白抜き文字の例。テキストが選択できていません。

ちなみにテキストに変換する手順は以下の通りです。
- まずは、スキャンしたPDFをひとまとめにしてしまいましょう。全PDFファイルを開いて左サムネール部分をドラッグ&ドロップでひとつのファイルにまとめます。
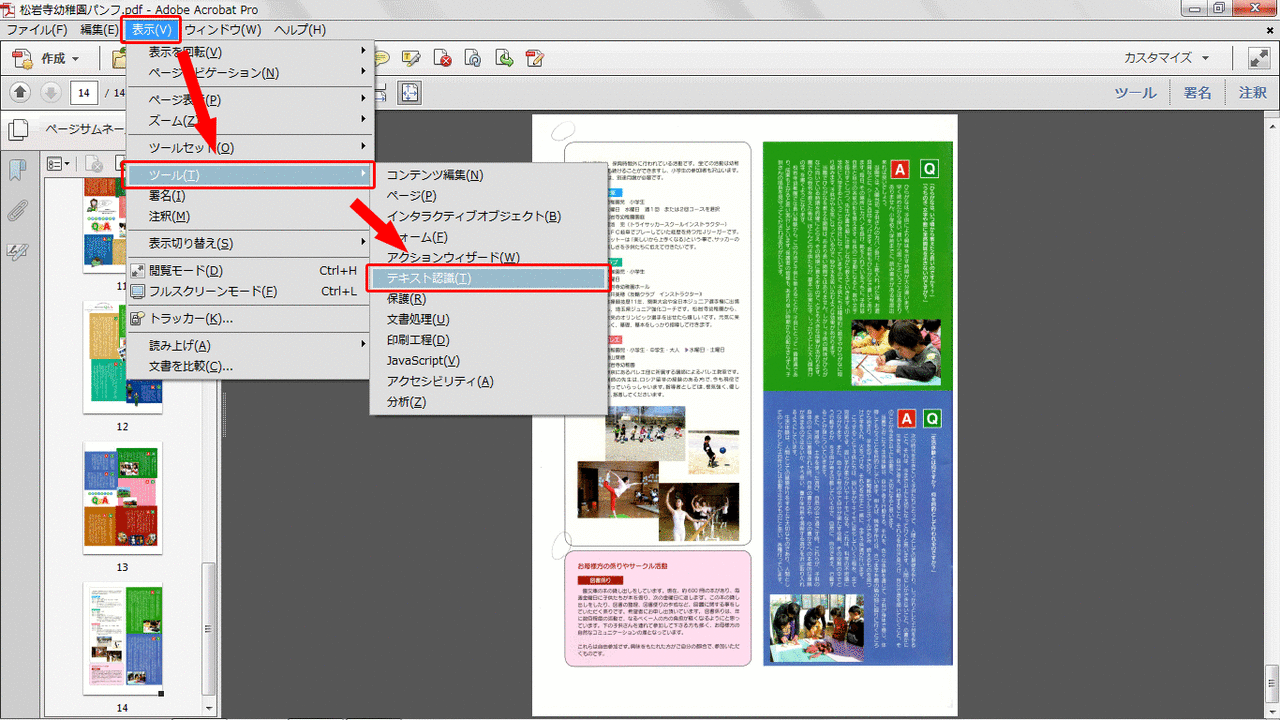
- 次に「表示」→「ツール」→「テキスト認識」とメニューを辿ります。
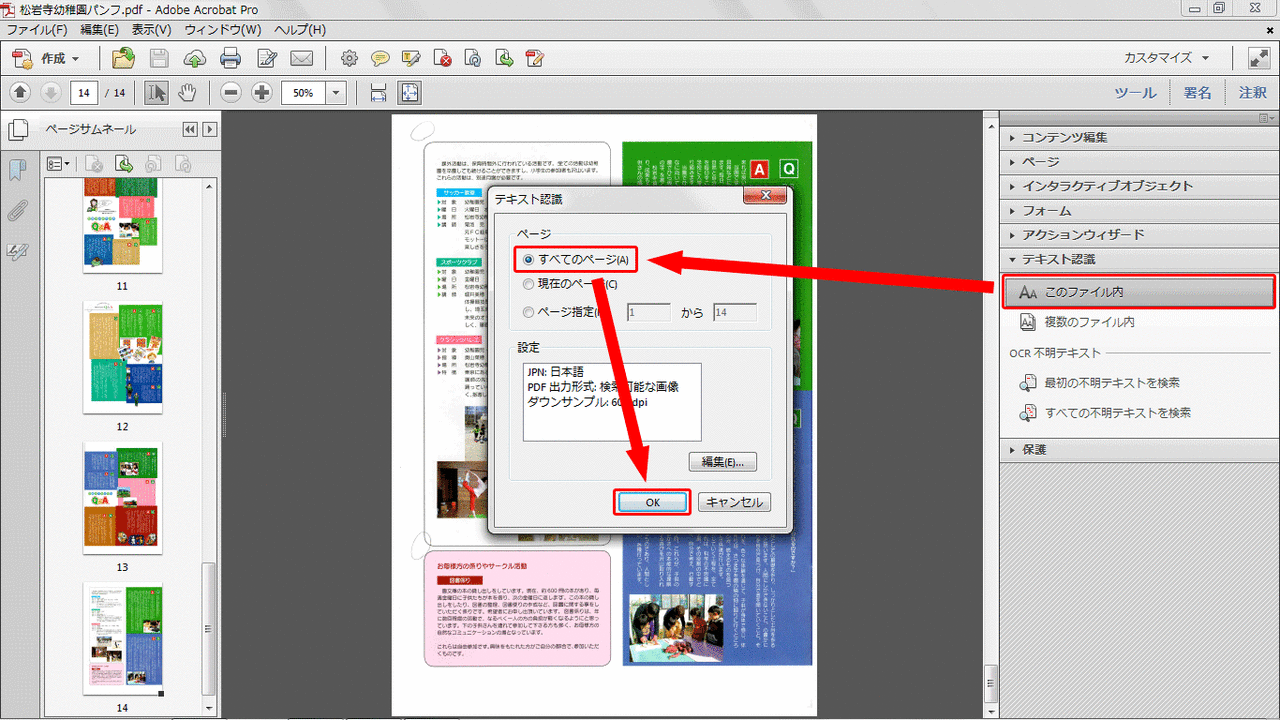
- 右にメニューが表示されるので「このファイル内」をクリックし、開いたダイヤログから「すべてのページ」をチェックし「OK」をクリックします。
- 暫く待つと変換が終了します。
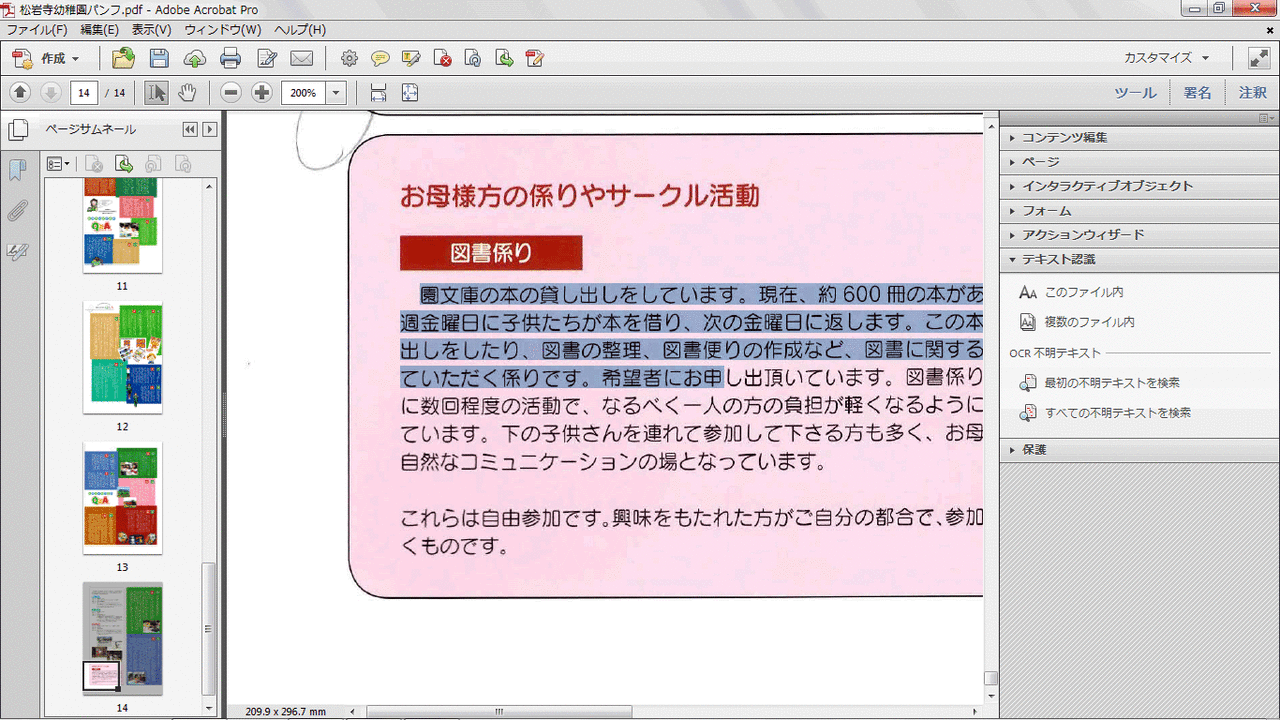
- 変換が終了するとドラッグ&ドロップでテキストが選択できるようになります。
- あとは、コピー&ペーストして使えばOKです。
実は、この機能知らなくて娘にアルバイトでテキスト入力やってもらっちゃいました。
一文字(2バイト)1円で計算したらなんと1万超に。
でも、OCRよりはずっと正確で助かりましたよ。
アドセンス広告メイン
関連記事
-

-
「iPhone」片手で拡大縮小する方法
1年以上前の記事です。内容が古い可能性があります。もう、今年はiPhone(アイ …
-
-
ブラインドタッチを覚えるための10のポイント
1年以上前の記事です。内容が古い可能性があります。先日より、ブラインドタッチを覚 …

-
-
Facebookとツイッターの連携はこれで行く!「Selective Tweets」
1年以上前の記事です。内容が古い可能性があります。以前、記事にしていたFaceb …

-
-
Androidアプリをアフィリエイトする方法
1年以上前の記事です。内容が古い可能性があります。忘れてました。Androidア …

-
-
もう面倒くさいからWindows10にアップグレードしたらとっても良かった
1年以上前の記事です。内容が古い可能性があります。巷では色々悪評のなくならない、 …

-
-
livedoor Blog(ライブドアブログ)で「記事をコピー」すると公開しちゃうゾ
1年以上前の記事です。内容が古い可能性があります。自分の場合、ブログを書くときは …

-
-
これからのSEOは被リンクでなく「テールワード」と「サテライトサイト」
1年以上前の記事です。内容が古い可能性があります。久しぶりにSEOのことを書こう …

-
-
内包されたDIVにmarginを設定すると親要素にも同じマージンが設定されることがある【CSS】
1年以上前の記事です。内容が古い可能性があります。これはわからんわ。 生徒さんの …

-
-
最近PVが伸びないのはGunosy(グノシー)対策してないから? Gunosy(グノシー)にブログを掲載させるコツ
1年以上前の記事です。内容が古い可能性があります。最近、PVが頭打ち。それどころ …

-
-
長距離高速深夜バス(夜行バス)に電源が付いているかどうかは座席の列数で判断。3列は付いている可能性大
1年以上前の記事です。内容が古い可能性があります。京都に来ています。







